self-hostedai
Ollama Fleet Manager
· Vitor Pontual · 1 min read
1 / 2
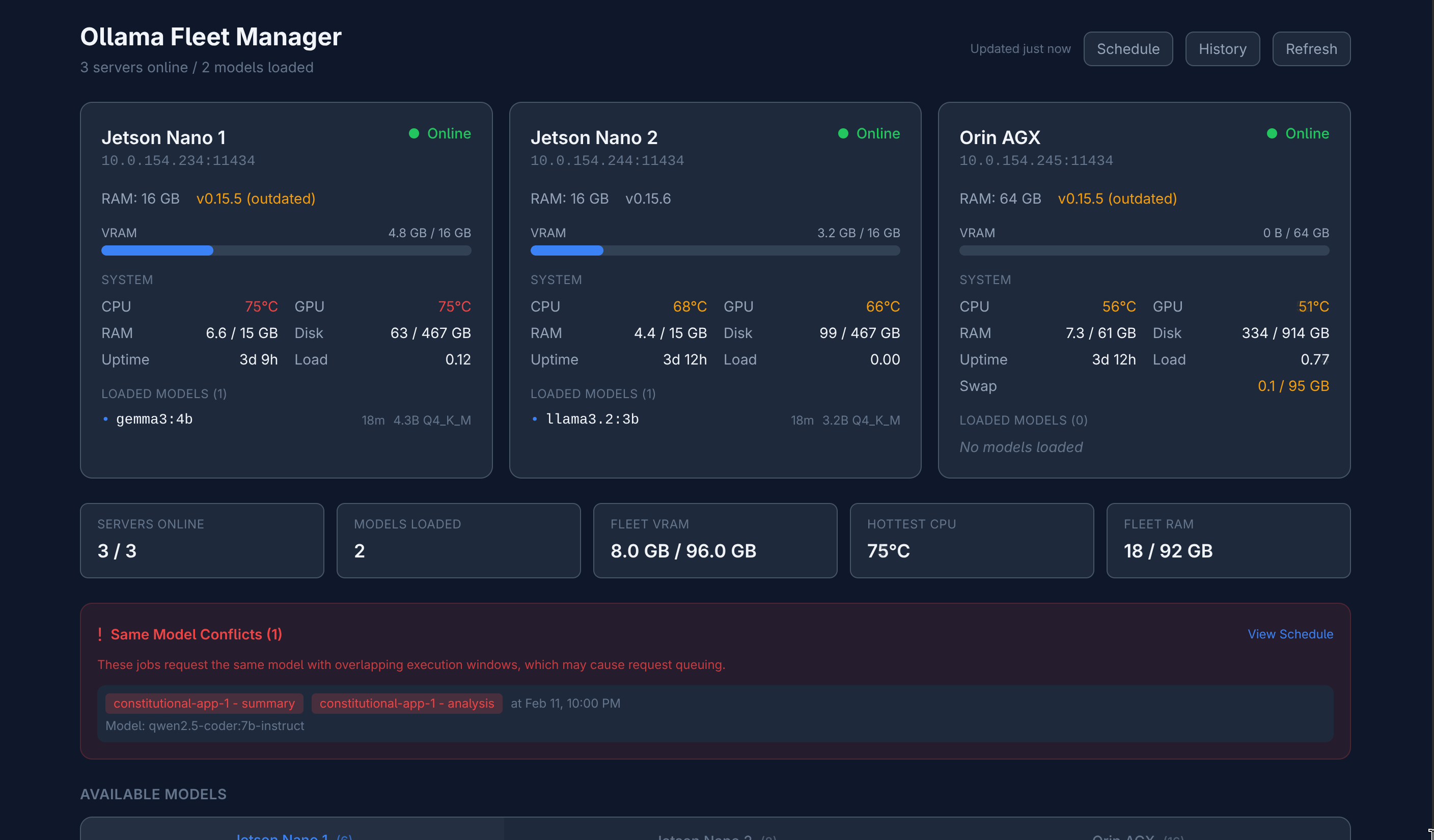
A dashboard and intelligent proxy for managing a fleet of Ollama GPU servers. Point any Ollama client at the proxy and it routes requests to the best available server automatically—no application changes needed.
- Intelligent request routing — prioritizes servers with model already loaded, then model on disk, then most free VRAM
- Real-time fleet monitoring — server status, loaded models, VRAM usage, CPU/GPU temperature, memory, disk, and uptime
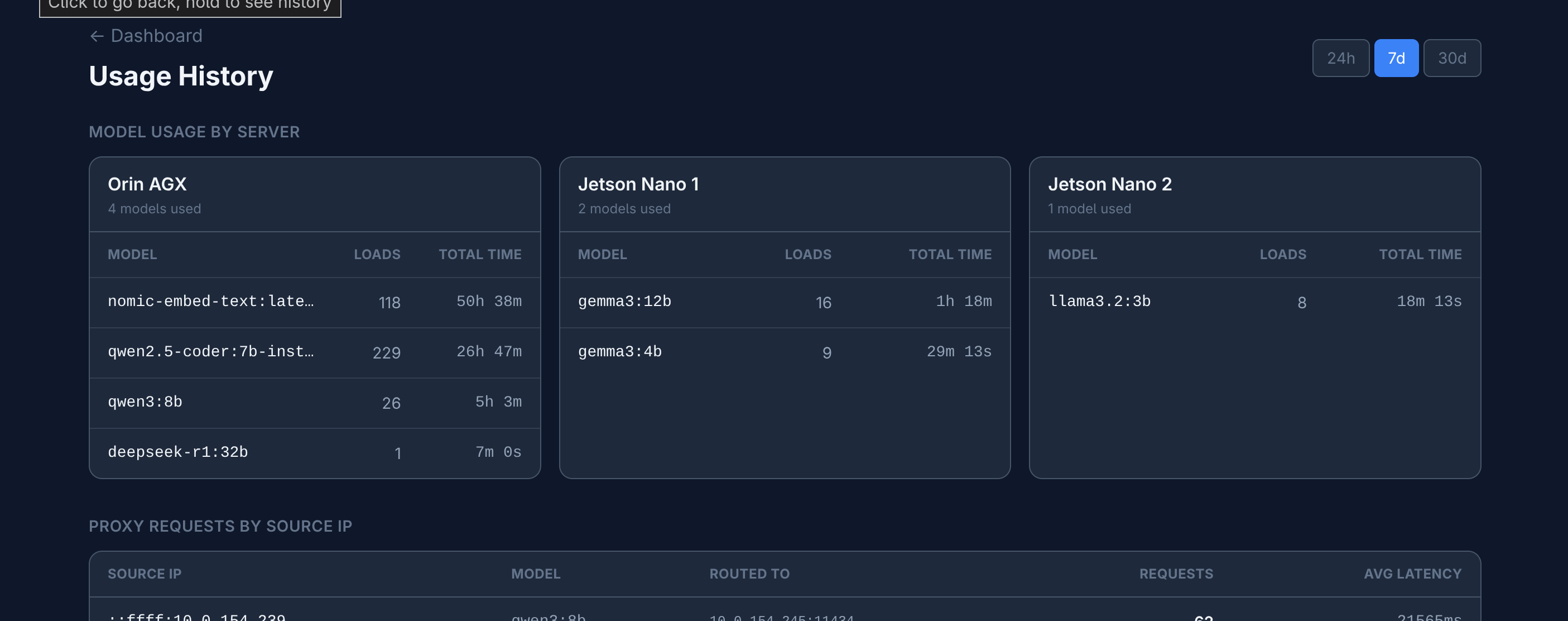
- Usage analytics — request volume, success rates, latency percentiles, and breakdowns by model, source, and server over 24h/7d/30d windows
- Request aggregation —
/api/tags,/api/ps, and/v1/modelscombine responses from all servers into a single unified list - Scheduled jobs — cron-based model scheduling with conflict detection across the fleet
- Telegram alerts — server offline/online, overheating, low memory, and reboot notifications
- Plugin system — extensible architecture for community plugins
- OpenAI API compatible — supports
/v1/*endpoints so OpenAI-compatible tools work out of the box